資料內(nèi)容:
1.1 什么是Scrapy
Scrapy是一個為了爬取網(wǎng)站數(shù)據(jù)、提取結(jié)構(gòu)性數(shù)據(jù)而編寫的應(yīng)用框架,可以應(yīng)用在包括數(shù)據(jù)挖掘、信息
處理或存儲歷史數(shù)據(jù)等一系列的程序中。它是用Python實(shí)現(xiàn)的,最初是為了頁面抓取(更確切來說,是網(wǎng)
絡(luò)抓取)所設(shè)計的,也可以用于獲取API所返回的數(shù)據(jù)(例如Amazon Associates Web Services)或者通用的
網(wǎng)絡(luò)爬蟲。
Scrapy的特點(diǎn)包括:
內(nèi)置支持使用擴(kuò)展的CSS選擇器和XPath表達(dá)式從HTML/XML源碼中選取提取數(shù)據(jù)
提供交互式shell控制臺,用于調(diào)試選擇器
內(nèi)置支持生成多種格式的導(dǎo)出文件(JSON、CSV、XML)并存儲在多種后端(FTP、S3、本地文件系統(tǒng))
強(qiáng)大的編碼支持和自動檢測,用于處理外國的、非標(biāo)準(zhǔn)的和損壞的編碼聲明
可擴(kuò)展性強(qiáng),可以通過signals和API(中間件、擴(kuò)展、管道)實(shí)現(xiàn)自定義功能
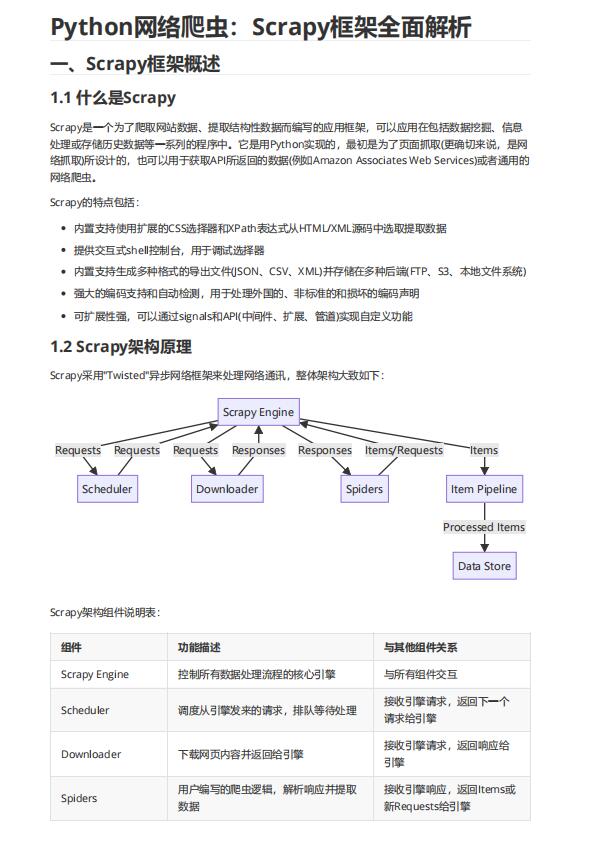
1.2 Scrapy架構(gòu)原理
Scrapy采用"Twisted"異步網(wǎng)絡(luò)框架來處理網(wǎng)絡(luò)通訊,整體架構(gòu)大致如下:

