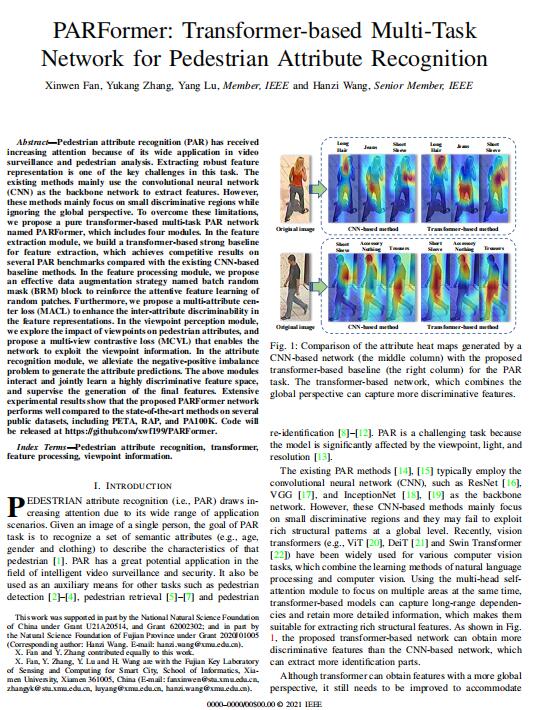
資料內(nèi)容:
PETA: It contains a total of 19, 000 pedestrian images
taken by real surveillance cameras [54]. These images are
randomly divided into 9, 500 training images, 1, 900 velidation
images, and 7, 600 test images. Each pedestrian image has
61 binary attributes and 4 multi-category attributes. Because
the distribution of some attributes is very uneven, the existing
methods mainly focus on 35 attributes of the 61 attributes.
PA100K: It is the largest open-source pedestrian attribute
dataset, with 26 pedestrian attributes annotated [55]. It con
tains 100, 000 pedestrian images collected by the surveillance
cameras, with 80, 000 images for training, 10, 000 images for
validation, and 10, 000 images for testing.
RAP: It has two versions, and the RAP-v1 dataset [51] is
used in our experiment. This dataset contains 41, 585 pedes
trian images collected from 26 indoor surveillance cameras,
including 69 binary attributes, while the existing methods
mainly focus on 51 attributes, and each of those is with a
proportion greater than 1%. The training set of this dataset
contains 33, 268 images, and the rest are used for testing.
According to the existing methods, we adopt five metrics
for evaluation: mean average precision (mA), accuracy (Accu),
precision (Prec), recall (Recall), and F1 score (F1)

